作为国内 OTA 的领头羊,携程每天都在服务着成千上万的旅行者。为了保障旅行者的出行,庞大的携程客服在其中扮演着十分重要的角色。但在客服的日常工作中,有一部分的行为是重复劳动,这对于客服来说是一种资源浪费。如何通过算法来提升客服效率成为技术一大挑战。
本场 Chat 将介绍智能算法如何辅助客服工作,并介绍QA问答背后的技术和难题,以及如何用机器学习和深度学习在提升用户体验和客服效率上进行落地。
本场 Chat 主要内容:
QA Chatbot 背后的技术细节和难题;
精细化运营——AI算法如何提升用户体验;
文本挖掘算法如何辅助客服工作。
作者简介:元凌峰,携程平台中心 AI 研发部资深算法工程师,负责携程智能客服算法研发,对 Chatbot 相关的 NLP 算法和推荐排序等算法感兴趣。2015年硕士毕业于上海交通大学图像模式研究所,后加入携程负责实时用户意图和小诗机等项目。
概述
作为国内 OTA 的领头羊,携程每天都在服务着成千上万的旅行者。为了保障旅行者的出行,庞大的携程客服在其中扮演着十分重要的角色。但在客服的日常工作中,有很大一部分的行为是重复劳动,这对于客服来说是一种资源浪费。如何从客服工作中解放生产力,提高生产效率成为技术需要解决的一大难题。
随着近几年深度学习算法突破和硬件的升级,人工智能技术在多个领域遍地开花,其中一大应用场景便是智能客服。2017 年初,携程开始大力推进客服智能化的技术研发,目前在酒店售后客服场景,智能客服已经能够解决 70 % 的问题,不仅提升了客服效率,在服务响应方面也有很大提升。
那么,机器学习或者深度学习在客服领域到底能做什么?怎么做?本文将围绕这两方面介绍携程在智能客服领域中的一些实践经验。
我们先回答这些算法在客服领域到底能做什么。
回答这个问题要回到客服聊天工具这个产品本身,用户在使用客服聊天工具时,最希望的是能够第一时间在客服界面上看到自己想咨询的问题,然后直接找到答案。如果第一眼没有看到想要的问题,那就希望在和 “ 客服 ” 交互过程中以最少的交互次数获取到需要的答案。
在这个过程中,算法不外乎要做的就是两件事:猜你所想,答你所问。
我们先说猜这件事,类似推荐,在用户还没有做出任何输入时,我们会根据用户的信息、当前上下文信息以及咨询的产品信息来猜测用户进入咨询界面时想问什么问题,从而得到一堆问题的排序展示给用户。
如果第一步没有猜到用户想要的问题,用户就会通过输入框来简单描述自己的情况和想要咨询的问题,在用户输入的过程中,我们也会结合用户输入的内容通过算法来实时猜测用户可能咨询的问题,并以 input suggestion 的方式给到用户。若上述都无法让用户找到自己想要的答案,那就是答这件事要解决的。
我们会采用 QA 模型对用户发送的话术内容进行分析和匹配,得到用户可能想问的问题,并反馈给用户。这样就完成了一个对话回合,但其实除了上述提到的几个点以外,还有很多地方需要算法参与,比如问题挖掘、关联问题推荐以及上下文对话等等。
下面我们就重点介绍几种常用的算法如何发挥作用。
Question - Answer Match
标准 Q 匹配模型是机器人进行交互的基础模型,对匹配率的要求较高。传统的做法直接根据关键词检索或 BM25 等算法计算相关性排序,但这些方法缺点是需要维护大量的同义词典库和匹配规则。后来发展出潜在语义分析技术(Latent Semantic Analysis,LSA[1,2]),将词句映射到低维连续空间,可在潜在的语义空间上计算相似度。
接着又有了 PLSA(Probabilistic Latent Semantic Analysis)[3]、LDA(Latent Dirichlet Allocation)[4]等概率模型,形成非常火热的浅层主题模型技术方向。这些算法对文本的语义表示形式简洁,较好地弥补了传统词汇匹配方法的不足。不过从效果上来看,这些技术都无法完全替代基于字词的匹配技术。
随着深度学习技术兴起后,基于神经网络训练的 Word2vec [5]来进行文本匹配计算引起了广泛的兴趣,而且所得的词语向量表示的语义可计算性进一步加强。但是无监督的 Word2vec 在句子匹配度计算的实用效果上还是存在不足,而且本身没有解决短语、句子的语义表示问题。
因此,研究者们开始研究句子级别上的神经网络语言模型,例如 Microsoft Research 提出的 DSSM 模型(Deep Structured Semantic Model)[6],华为实验室也提出了一些新的神经网络匹配模型变体[7,8,9],如基于二维交互匹配的卷积匹配模型。中科院等研究机构也提出了诸如多视角循环神经网络匹配模型(MV - LSTM)[10]、基于矩阵匹配的的层次化匹配模型 MatchPyramid [11]等更加精致的神经网络文本匹配模型。虽然模型的结构非常多种,但底层结构单元基本以全链接层、LSTM、卷积层、池化层为主(参考论文[12,13,14,15]的做法)。
分类和排序
在语义模型的训练框架里,大致可以分为两类:分类和排序。
采用分类的方法,一般最后一层接的是多类别的 softmax,即输入是用户 Q,分类结果是所属的标准 Q 类别。
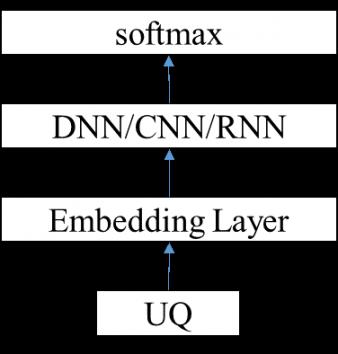
Figure 2 基于分类的模型结构
排序学习有三种类型:point - wise,pair - wise 和 list - wise。在QA中我们常用的是 point - wise 和 pair - wise。其中 point - wise 的方法直接把问题转换成二分类,判断当前用户问题是否属于带匹配的问题,最后根据隶属概率值可以得到问题的排序。
而 pair - wise 学习的是(uq,sq+)和(uq,sq-)两两之间的排序关系,训练目标是最大化正样本对和负样本对的距离:
maxL=||f(uq,q+ )-f(uq,q- )||d
其中f(·)表示某种距离度量。
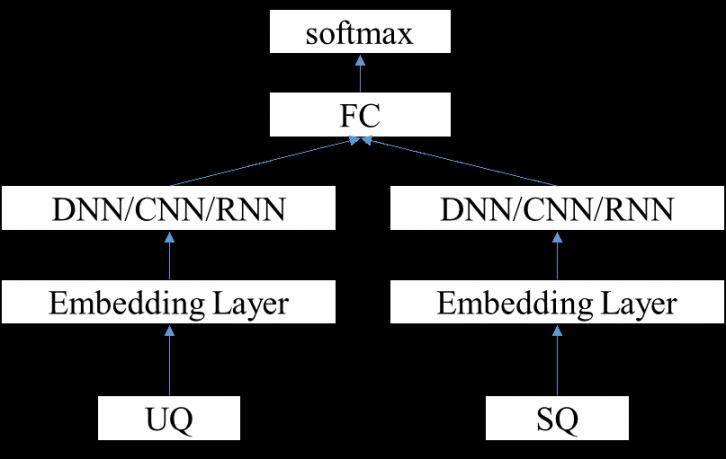
Figure 3 基于 point - wise 的模型结构
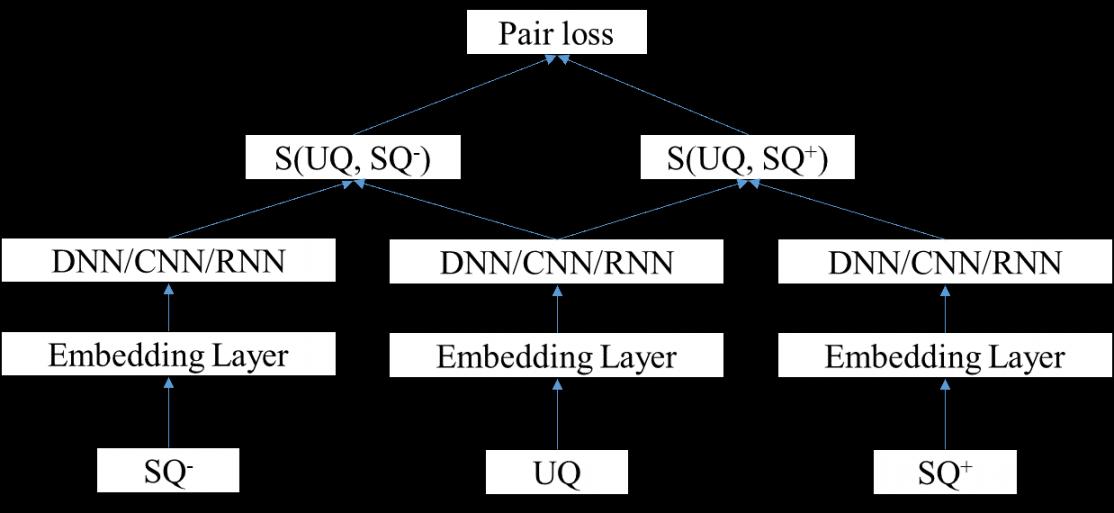
Figure 4 基于 pair - wise 的模型结构
单轮和上下文
一个流畅的会话是需要机器人拥有上下文多轮对话的能力,然而目前大部分 QA 机器人都是基于单轮匹配,如果用户继续上一个问题补充提问,单轮 QA 模型则会断章取义,无法准确识别当前句的准确意图。因此需要把上下文信息进行表示计算,实现多轮匹配模型。
提到多轮对话场景,大家都会想到 Task 任务式对话。但二者在上下文表示方面还是存在一些差异。Task(goal - driven system)是根据预定义的槽位和状态来表示上下文,并且依照某个业务逻辑的对话管理策略(也可以通过 POMDP [16]的方法来构建策略)来引导用户到想要搜索的内容。而 QA(non - goal - driven system)不是面向槽管理的,而是根据用户会话意图来调整对话过程。
在 QA 的上下文会话管理方法中,大致可分为两个方向,一个是 Rule - Based [17]的上下文模型;另一个是 Model - Based [18,19]的上下文模型。
Rule - Based
通过预定义一些先验知识来表示上下文,在会话中不断修改上下文的先验知识并根据上下文记录信息来重排序。
Model - Based
Model - Based 相对于 Rule - Based 的好处就是能够提升泛化能力。
有研究者[18,19]就利用模型这种特性,把上下文信息表征在向量里,并通过层次化模型来学习和推断。
该模型主要有三个结构:句子级 encoder 模型、context 级别 encoder 模型以及 response decoder 模型。其中 context encoder 模型是解决上下文信息的关键,整个模型用数学模型表示如下:
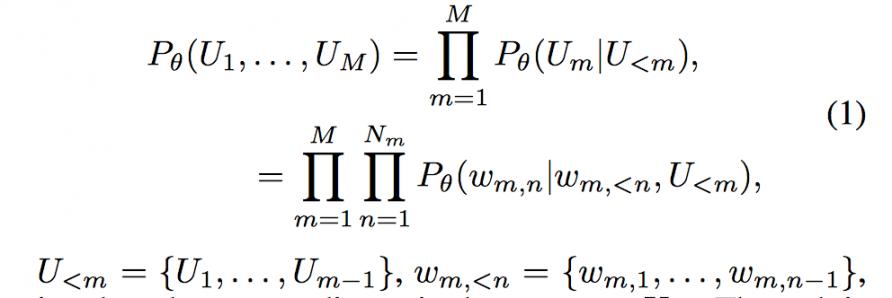
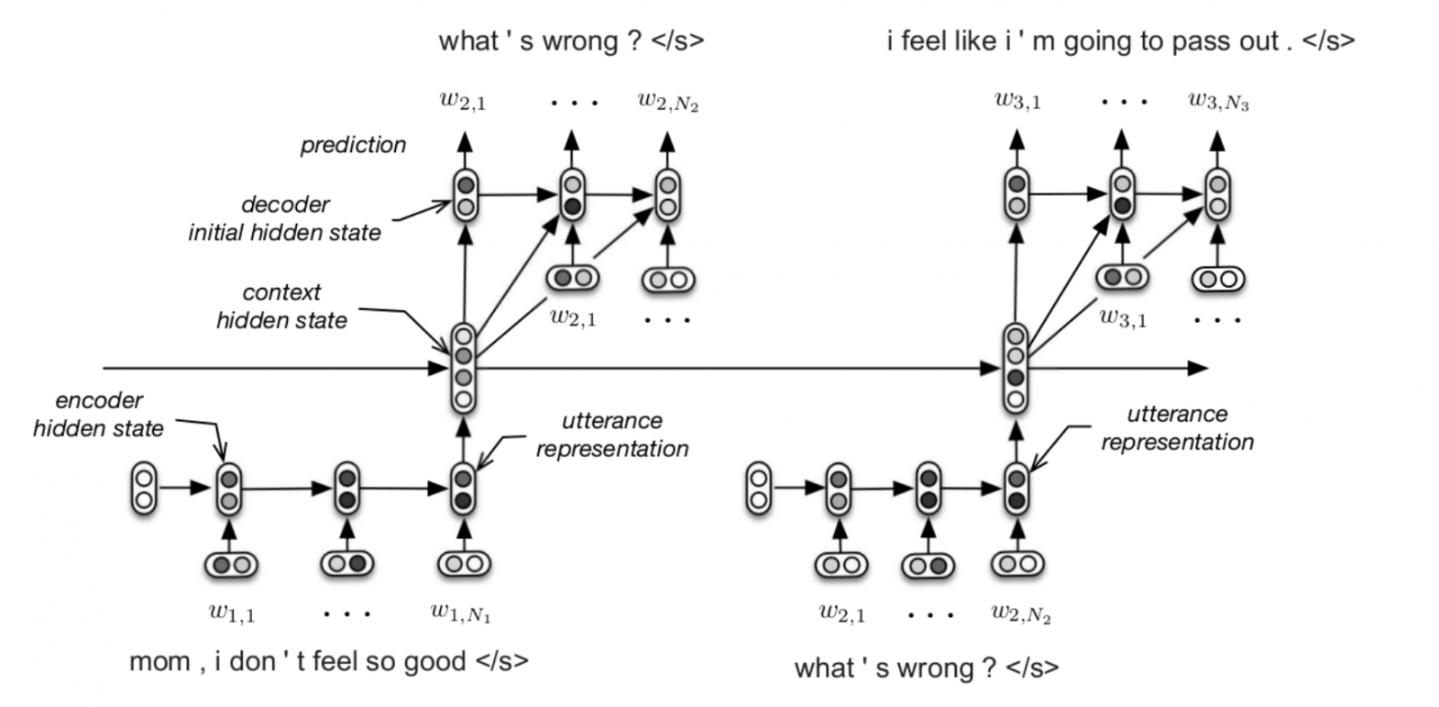
基于我们的场景对该模型稍作修改并训练后得到效果如下图。

Input suggestion
输入联想在搜索引擎或者商品搜索中有着十分重要的应用场景,但客服场景的联想提示又区别于搜索,用户的输入是各式各样的,联想结果不一定和用户输入的在词语上完全一致,只需语义上一致即可,而且是能够猜中用户意图。下面聊聊我们在该场景迭代的三种算法。
第一版本采用最常用的 Trie 树结构。字典树的结构简单实用。在搜索中,可以把所有的候选词条建立一个字典树,然后根据用户输入的前缀到 Trie 树中检索候选集,展示给用户。该结构优点是简单有效,能够快速上线。但缺点就是召回率较低,这是因为字典树要求用户输入的词语必须和候选集合里的短语句子要有一致的前缀。对此我们也做了泛化优化,例如去除掉停用词或者无意义词语等,尽可能提高召回。但提升有限。
第二阶段,我们直接采用 point - wise 的排序模型。因为第一阶段的数据积累和人工标注,我们已经有了一定的历史曝光点击数据。考虑到线上联想的请求性能要求较高,我们先尝试了逻辑回归模型。
在特征方面,我们主要抽取了三类特征:一类是基于 word2vec 得到的句子特征,另一类是传统的 TF - IDF 特征,最后一类是重要词汇特征(这类特征是通过数据挖掘得到的对应场景的重要词)。
该模型上线后整体的使用率比字典树有了明显提升,尤其召回率大幅度提高。
但是,第二阶段的模型仍然存在很多缺陷,我们把线上的曝光未点击数据分析了下,发现如下问题:
-线上存在很多拼音汉字混搭的case,模型没有解决能力;
-用户输入的话术存在很多错别字;
-联想请求场景以超短文本为主,大都集中在 2 - 6 个字 。
微软的 DSSM 模型在解决短文本语义匹配上有很好的效果,该模型主要亮点引入了 word hashing 操作,该操作能够很好的解决了 OOV(out of vocabulary)问题。其次就是深度神经网络增强了特征的表达能力,该模型计算图如下:
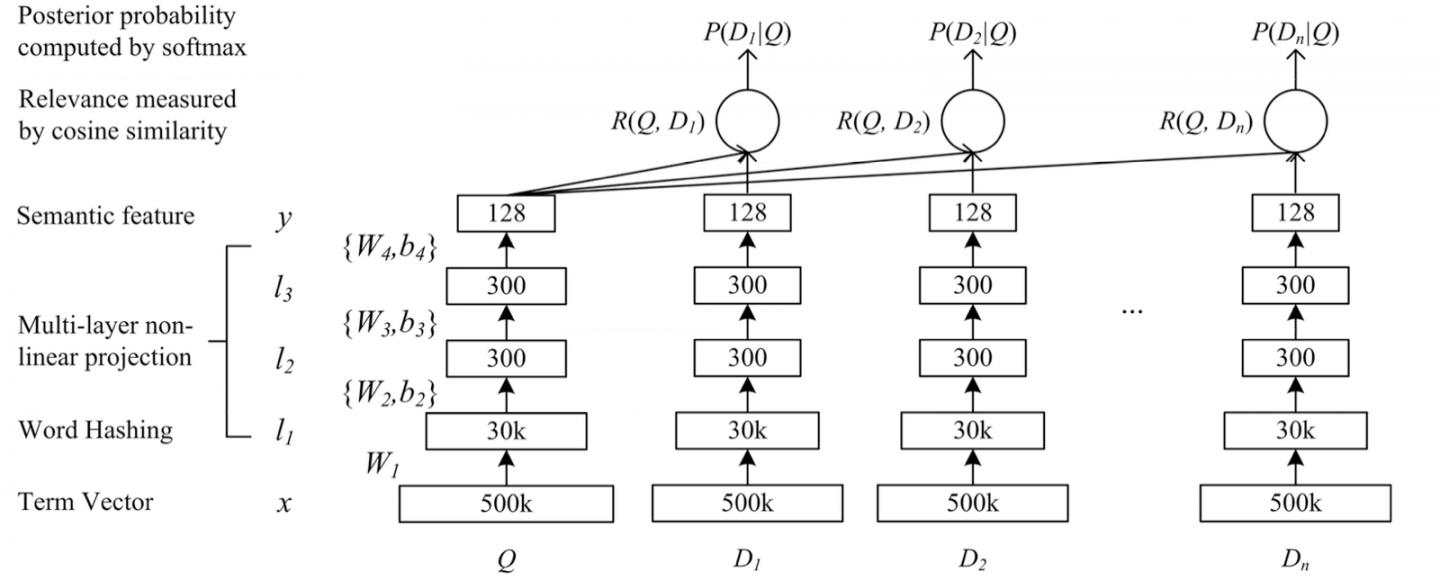
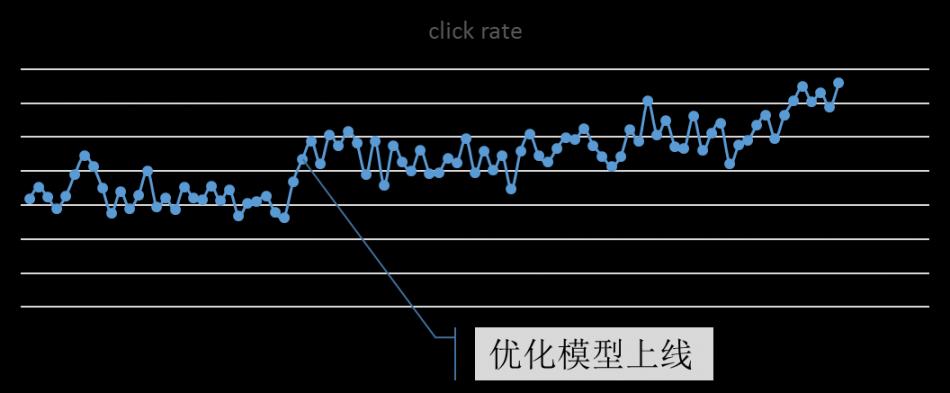
该模型上线后带来显著提升,整个输入联想场景的迭代效果如图。
总结
限于篇幅,除了上述提到的几种场景,机器学习和深度学习算法还在其他多个场景中辅助携程客服的工作,帮助提升客服工作效率和用户体验。
人工智能并不是新兴的黑科技,只不过近几年深度学习的快速发展让这个词重新活跃在大众视野中。尼尔逊教授对人工智能下了这样一个定义:“人工智能是关于知识的学科――怎样表示知识以及怎样获得知识并使用知识的科学。”
我们更愿意把人工智能看成是人工 + 智能算法 + 数据的一个综合体。算法工程师的定义不是简简单单懂算法就可以,而是要懂得如何用算法去优化人工提高效率,如何用算法去挖掘有效信息,紧密地让数据、算法、人工形成一个闭环。
Reference
[1] Dennis S, Landauer T, Kintsch W, et al. Introduction to latent semantic analysis[C]//Slides from the tutorial given at the 25th Annual Meeting of the Cognitive Science Society, Boston. 2003.[2] Deerwester S, Dumais S T, Furnas G W, et al. Indexing by latent semantic analysis[J]. Journal of the American society for information science, 1990, 41(6): 391-407.[3] Hofmann T. Unsupervised learning by probabilistic latent semantic analysis[J]. Machine learning, 2001, 42(1-2): 177-196.[4] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of machine Learning research, 2003, 3(Jan): 993-1022.[5] Mikolov T, Chen K, Corrado G, et al. Efficient estimation of word representations in vector space[J]. arXiv preprint arXiv:1301.3781, 2013.[6] Huang P S, He X, Gao J, et al. Learning deep structured semantic models for web search using clickthrough data[C]//Proceedings of the 22nd ACM international conference on Conference on information & knowledge management. ACM, 2013: 2333-2338.[7] Lu Z, Li H. A deep architecture for matching short texts[C]//Advances in Neural Information Processing Systems. 2013: 1367-1375.[8] Ji Z, Lu Z, Li H. An information retrieval approach to short text conversation[J]. arXiv preprint arXiv:1408.6988, 2014.[9] Hu B, Lu Z, Li H, et al. Convolutional neural network architectures for matching natural language sentences[C]//Advances in neural information processing systems. 2014: 2042-2050.[10] Wan,Shengxian, Yanyan Lan, Jiafeng Guo, Jun Xu, Liang Pang, and Xueqi Cheng."A Deep Architecture for Semantic Matching with Multiple PositionalSentence Representations." In AAAI, pp. 2835-2841. 2016.[11] Pang,Liang, Yanyan Lan, Jiafeng Guo, Jun Xu, Shengxian Wan, and Xueqi Cheng."Text Matching as Image Recognition." In AAAI, pp. 2793-2799. 2016.s[12] Feng M, Xiang B, Glass M R, et al. Applying deep learning to answer selection: A study and an open task[J]. arXiv preprint arXiv:1508.01585, 2015.[13] Lai S, Xu L, Liu K, et al. Recurrent Convolutional Neural Networks for Text Classification[C]//AAAI. 2015, 333: 2267-2273.[14] Santos C, Tan M, Xiang B, et al. Attentive pooling networks[J]. arXiv preprint arXiv:1602.03609, 2016.[15] Kim Y. Convolutional neural networks for sentence classification[J]. arXiv preprint arXiv:1408.5882, 2014.[16] Young S, Gašić M, Thomson B, et al. Pomdp-based statistical spoken dialog systems: A review[J]. Proceedings of the IEEE, 2013, 101(5): 1160-1179.[17] Langley P, Meadows B, Gabaldon A, et al. Abductive understanding of dialogues about joint activities[J]. Interaction Studies, 2014, 15(3): 426-454.[18] Serban I V, Sordoni A, Bengio Y, et al. Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models[C]//AAAI. 2016, 16: 3776-3784.[19] Sordoni A, Galley M, Auli M, et al. A neural network approach to context-sensitive generation of conversational responses[J]. arXiv preprint arXiv:1506.06714, 2015.
阅读全文: http://gitbook.cn/gitchat/activity/5b502b40f5b40e2a9fc8d402
一场场看太麻烦?订阅GitChat体验卡,畅享300场chat文章!更有CSDN下载、CSDN学院等超划算会员权益!点击查看